In Step 0, I basically scraped data from PDFs using pyplumber and then made word clouds using Pandas.
It has been a few years since I used Pandas. I had forgotten how similar it was to R.
Given the similarities, my next steps will be to convert the text into a somewhat meaningful CSV that can then be loaded as a dataframe. Once the CSV is a dataframe then the numeromancy can commence. Ideally, I’d like to use just Python tools, but bash is very quick for some data cleaning tasks.
Step 1:
I don’t recall off hand what I used for past endeavors with sentiment analysis – but the TextBlobs library has really made life super easy. Namely, it simplifies working with Python’s NLTK and implementing spiffy extras such as finding the polarity and subjectivity of sentences.
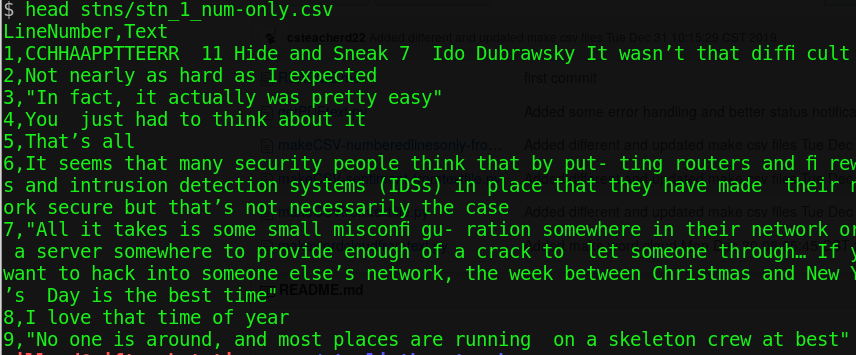
First the text is read in. Then newlines from the text are removed and the text is split up into new lines by periods. [Yes, this may be awkward given other possible terminators such as question marks. But, what dis-proportionality is generated by rhetorical questions??] The text is then treated as a file object. I created an intermediary python program to save this as a CSV with just text and line numbers, which could be used for other analyses.
The next step is to actually generate the sentiments. Basically, each textblob object has a sentiment quality with polarity and subjectivity requirements. For transparency purposes, i.e. to remember what I did six months from now, I used functions to return the polarity and subjectivity values. Then use the dataframe apply function (this is so similar to R) to add the values as columns.
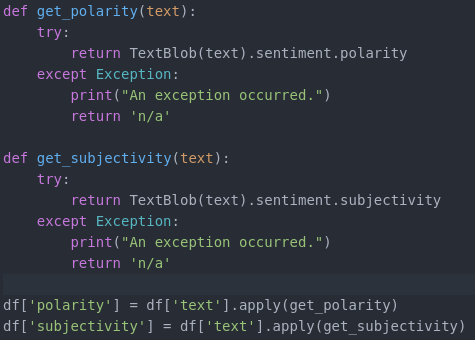
In essence, the python script that I shared here:
- passes the name of a file as a command line argument [sys.argv[1]]
- reads in that file
- removes all new lines
- add new lines at each ‘. ‘ (period followed by a space)
- makes sure the text plays nice as Unicode
- treats the text as a file object
- iterates through the file object adding each line as part of a row in a dataframe
- the methods (getters) for polarity and subjectivity (i.e. get_polarity and get_subjectivity) are used to add those values individually to the dataframe
- the dataframe is exported as a CSV