Datascraping and visualization with Python – for students
Part I – Organizing data and word clouds
The goal is to develop a basic lesson that:
- allows students to explore topics of their choice
- enables their ability to meaningful scrape and visualize large amounts of web data
- requires that the students think i.e. abstract and problem solve in a programmatic space [try to limit the cookie cutterness]
Moreover, I would like to have some “value added”:
- let’s see if we can’t make a few discoveries – such as:
- visualizing valence relations
- identifying and visualizing relational framing in texts
The progression will (most likely) be:
- grab the text
- make a word cloud based on frequency
- identify valences
- visualize valences
- identify relational frames
- graph the valences/relational frames using cumulative sums [ala Skinner]
Oy, it’s been about 200 years since I last wrote a blogpost. They have since been lost to the ether. I am sure they would have been incredibly useful for their target audience i.e. novice python programmers needing to create SQL data bases by scraping information from PDFs in order to track student grades….
Step 0: What am I going to scrape? I had originally intended to start by scraping Tweets from the Twittersphere. However, I am not sure what a baseline even looks like in non-twittered text. Let’s start by scraping the text from the “Stealing the Network” series. It’s a classic and I am curious to see what the actual valences and relations in the text.
Step 1:
Let’s use pdfplumber to grab the text. I’ll want to evaluate whole text as well as by chapter (each chapter has a separate author and attack).
Extracting the text works pretty well using this pdftext scraper. Basically, I created a little pdf scraper that accepts the file name as input and creates a file with that name + “.txt” that has all the text excluding some bits at the margins.
This will help to iterate through files. I used pdftk to uncompress the complete zip and qpdf to split the book into chapters for analysis. 
I then iterated through grabbing the text chapter by chapter (using a bash for loop and the Python program i.e. for stn in $(ls stn*pdf); do ./getPDFtext.py “$stn”; done . Then I iterated using the same process, and makewordcloud.py, to create a wordcloud for each chapter. Using basically default color settings and no stop words (i.e. not removing specific words), the word clouds looked nice.
Here is a montage from Book 1 – How to Own the Box:  Here is a montage from Book 2 – How to Own a Continent:
Here is a montage from Book 2 – How to Own a Continent:
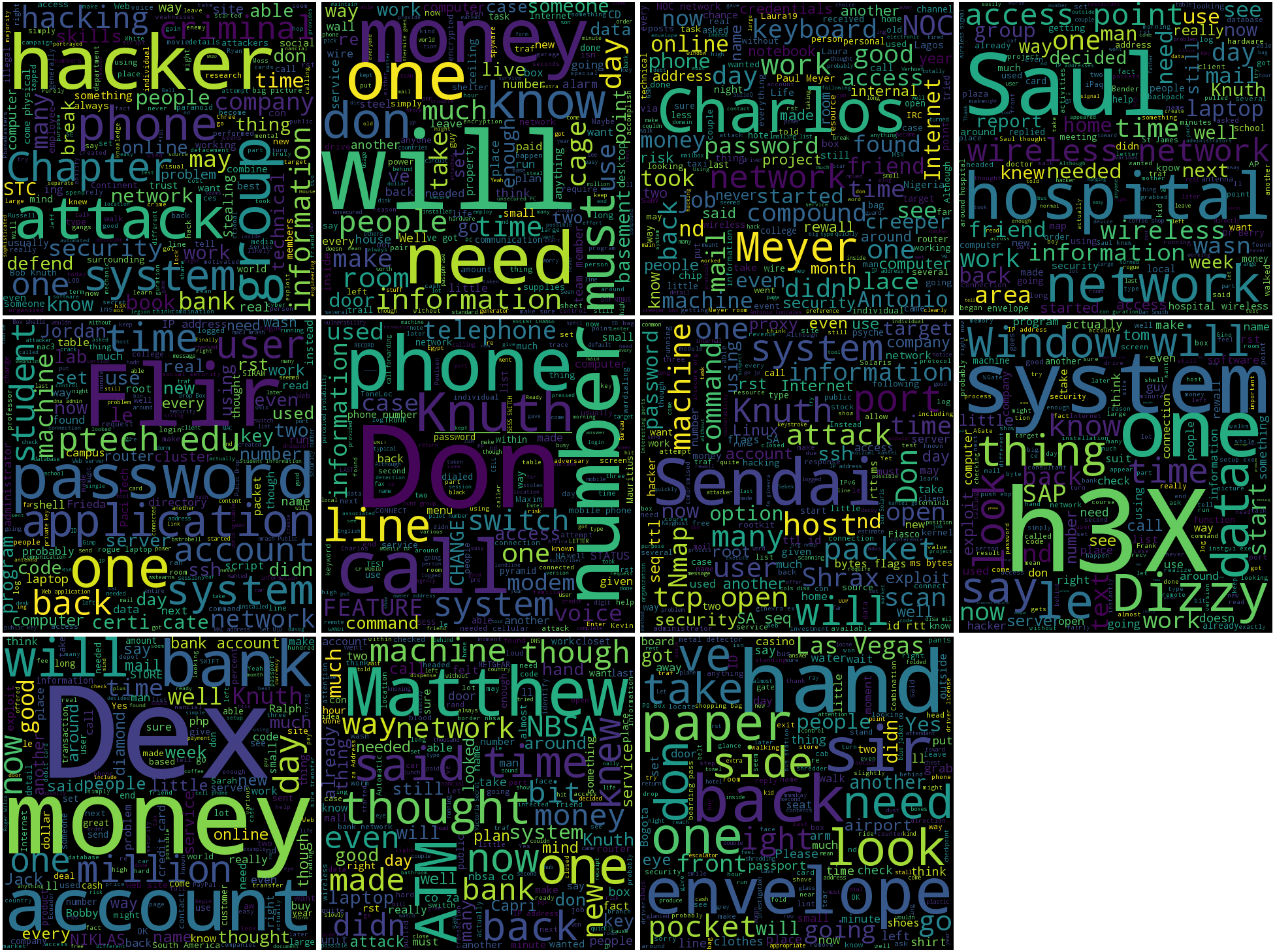
Here is a montage from Book 3 – How to Own an Identity:

Here is a montage from Book 4 – How to Own an Identity:
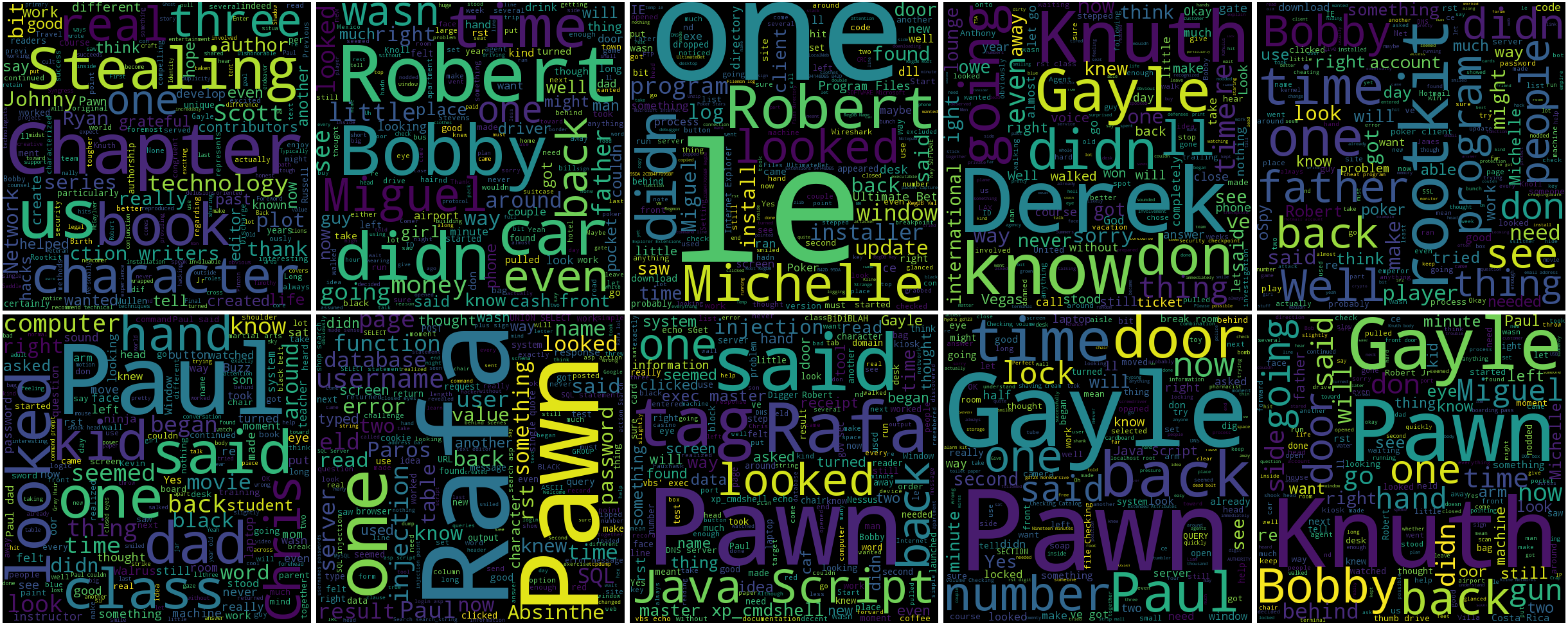
Step 2:
This is where things will hopefully get a bit more interesting. In the past I did a bit with R, but apparently all the cool stuff can be done with Pandas and other Python libraries. [And the students and their parents might balk at R.]